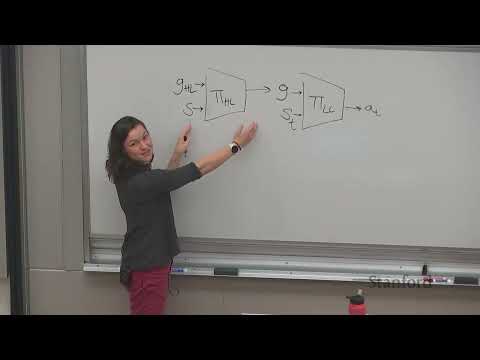На семинаре в Стэнфордском университете ведущий исследователь представил передовые подходы к безопасному и эффективному машинному обучению в физическом мире. В центре внимания оказалась проблема преодоления рисков при обучении реальных агентов — от автономных роботов до линейных ускорителей элементарных частиц, где цена ошибки критически высока. Спикер подробно разобрал механизмы безопасной байесовской оптимизации, мета-обучения и управления неопределенностью, позволяющие алгоритмам эффективно осваивать новые среды без риска разрушения оборудования.
🌍 Вызов реального мира: почему ИИ до сих пор «живет в матрице» 0:10
Современные модели машинного обучения и искусственного интеллекта демонстрируют впечатляющий уровень универсальности, выходя далеко за рамки простых задач классификации изображений или перевода текстов <a class="ts" data-seconds="48" href="#t=48" title="Смотреть с 0:48" aria-label="Смотреть с 0:48"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Сегодня нейросети способны сочинять стихи и рэп-композиции о субмодулярной оптимизации или создавать фотореалистичные видео по текстовому описанию. Однако перенос этих достижений в физический мир — в такие сферы, как взаимодействие человека и робота, медицинские рекомендации, научные открытия и точное земледелие — сопряжен с огромными трудностями <a class="ts" data-seconds="76" href="#t=76" title="Смотреть с 1:16" aria-label="Смотреть с 1:16"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Как только алгоритмы начинают сталкиваться с реальной средой, ставки резко возрастают, а любые сбои становятся проблематичными. Центральной парадигмой машинного обучения в этих контекстах выступает обучение с подкреплением (Reinforcement Learning, RL) <a class="ts" data-seconds="103" href="#t=103" title="Смотреть с 1:43" aria-label="Смотреть с 1:43"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. В этой модели агент взаимодействует со средой, совершает действия, меняет марковские состояния и получает награду. Ключевая проблема здесь заключается в том, что агент изначально не знает, как устроен мир, и сталкивается с дилеммой исследования и эксплуатации (exploration vs. exploitation) <a class="ts" data-seconds="128" href="#t=128" title="Смотреть с 2:08" aria-label="Смотреть с 2:08"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Ему приходится балансировать между экспериментированием для изучения последствий своих действий и использованием уже накопленных знаний для достижения наилучшего результата.
В последние годы академическое сообщество наблюдало за выдающимися успехами RL в играх, а также в сложных робототехнических приложениях. По словам докладчика, исследователи из Цюриха научили роботов совершать пешие прогулки по пересеченной местности и управлять дронами быстрее, чем это делают люди-пилоты <a class="ts" data-seconds="140" href="#t=140" title="Смотреть с 2:20" aria-label="Смотреть с 2:20"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Тем не менее в классическом представлении алгоритмов обучения с подкреплением кроется серьезное допущение. Спикер иронично отмечает, что в действительности ИИ-агент «живет в матрице» <a class="ts" data-seconds="168" href="#t=168" title="Смотреть с 2:48" aria-label="Смотреть с 2:48"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Для успешного обучения ему необходим невероятно точный симулятор, детально описывающий законы окружающего мира. В реальных же задачах, включая автономные лаборатории и научные эксперименты, симуляции либо слишком грубы, либо безумно дороги. В физическом пространстве любое исследование обходится дорого и может быть опасным <a class="ts" data-seconds="195" href="#t=195" title="Смотреть с 3:15" aria-label="Смотреть с 3:15"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Это заставляет ученых искать подходы, которые сочетали бы в себе максимальную эффективность выборки (sample efficiency) и строгие гарантии безопасности.
🔬 Кейс SwissFEL: оптимизация лазера на свободных электронах 3:44
В качестве главного практического примера безопасного обучения спикер привел совместный проект с Институтом Поля Шеррера (Paul Scherrer Institute) в Швейцарии <a class="ts" data-seconds="224" href="#t=224" title="Смотреть с 3:44" aria-label="Смотреть с 3:44"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Исследователи работали со SwissFEL — уникальным лазером на свободных электронах. Эта установка представляет собой линейный ускоритель частиц длиной 700 метров, который генерирует рентгеновские импульсы экстремально короткой фемтосекундной длительности (одна миллионная от миллиардной доли секунды) <a class="ts" data-seconds="237" href="#t=237" title="Смотреть с 3:57" aria-label="Смотреть с 3:57"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
С помощью этих ультракоротких вспышек ученые могут получать изображения сверхбыстрых процессов, например, видеть, как молекулы взаимодействуют друг с другом в ходе химической реакции <a class="ts" data-seconds="250" href="#t=250" title="Смотреть с 4:10" aria-label="Смотреть с 4:10"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Подобные исследования критически важны для разработки новых лекарств и открытия передовых материалов.
SwissFEL — это невероятно сложное и хрупкое устройство. Свойства его излучения зависят от точно выверенной конфигурации множества магнитов, часть из которых физически перемещается в пространстве. Параметры пучка постоянно колеблются под воздействием тончайших изменений внешней среды, таких как температура и влажность воздуха <a class="ts" data-seconds="264" href="#t=264" title="Смотреть с 4:24" aria-label="Смотреть с 4:24"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Установку нельзя настроить один раз и забыть: ее конфигурацию необходимо непрерывно адаптировать под требования конкретного целевого эксперимента.
При этом процесс настройки является критически опасным для самого оборудования. Ошибочные действия оператора или алгоритма могут физически повредить магниты и полностью уничтожить дорогостоящую установку <a class="ts" data-seconds="277" href="#t=277" title="Смотреть с 4:37" aria-label="Смотреть с 4:37"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. К счастью, лазер оснащен огромным количеством датчиков и мониторов потерь пучка, фиксирующих, насколько близко система подходит к нарушению критических ограничений.
Главная сложность заключается в том, что базовые законы физики процесса поддаются симуляции, но математическое моделирование с требуемым уровнем точности требует колоссальных вычислительных мощностей <a class="ts" data-seconds="303" href="#t=303" title="Смотреть с 5:03" aria-label="Смотреть с 5:03"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. С учетом того, что параметры внешней среды меняются динамически, рассчитывать настройки в симуляторе в реальном времени невозможно. Настройку и эксперименты приходится проводить непосредственно на работающем оборудовании.
🧮 Безопасная байесовская оптимизация и калибровка неопределенности 5:16
Абстрактно эту задачу можно представить как оптимизацию «черного ящика». На вход подаются настраиваемые параметры ($\Delta t$), а на выходе измеряется награда (интенсивность пучка) и показатели безопасности с датчиков потерь <a class="ts" data-seconds="329" href="#t=329" title="Смотреть с 5:29" aria-label="Смотреть с 5:29"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Ни целевая функция награды, ни точные границы ограничений не известны алгоритму заранее. Задача сводится к нелинейной оптимизации с неизвестными ограничениями, где критически важно сохранять безопасность (допустимость состояния) на каждом шагу <a class="ts" data-seconds="345" href="#t=345" title="Смотреть с 5:45" aria-label="Смотреть с 5:45"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Без априорных предположений эта задача математически некорректна и не имеет решений. Чтобы сделать ее решаемой, исследователи применили байесовский подход, моделируя неопределенность неизвестных функций <a class="ts" data-seconds="372" href="#t=372" title="Смотреть с 6:12" aria-label="Смотреть с 6:12"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. В рамках байесовской оптимизации неизвестные награды и ограничения наделяются априорным распределением случайного процесса, что позволяет алгоритму действовать осторожно и осознанно.
В качестве базовой модели ученые использовали гауссовские процессы (Gaussian Processes, GP), хотя подход применим и к байесовским нейросетям <a class="ts" data-seconds="397" href="#t=397" title="Смотреть с 6:37" aria-label="Смотреть с 6:37"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Математический механизм работает на основе доверительных интервалов:
- Оценка ограничений: алгоритм использует пессимистичную (нижнюю) границу доверительного интервала для безопасных зон, что позволяет статистически аппроксимировать гарантированно безопасную область с высокой вероятностью
<a class="ts" data-seconds="424" href="#t=424" title="Смотреть с 7:04" aria-label="Смотреть с 7:04"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. - Оценка наград: для целевой функции используется оптимистичная (верхняя) граница, указывающая на потенциально наиболее выгодные параметры
<a class="ts" data-seconds="436" href="#t=436" title="Смотреть с 7:16" aria-label="Смотреть с 7:16"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Обычный поиск в рамках безопасной зоны быстро приводит к застреванию в локальных субоптимальных решениях. Чтобы избежать этого, в алгоритм заложили концепцию «расширителей» (expanders) <a class="ts" data-seconds="465" href="#t=465" title="Смотреть с 7:45" aria-label="Смотреть с 7:45"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. У алгоритма появляется стимул исследовать границы текущей безопасной зоны, чтобы статистически сертифицировать новые области пространства параметров и открывать путь к глобально лучшим конфигурациям.
Для работы этих математических гарантий модели обязаны быть хорошо откалиброванными: истинные физические функции должны строго укладываться в доверительные интервалы байесовской модели <a class="ts" data-seconds="492" href="#t=492" title="Смотреть с 8:12" aria-label="Смотреть с 8:12"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Если модель раскалибрована, реальные параметры могут выйти за безопасные границы. Спикер подчеркнул, что обеспечение равномерной калибровки bounds во всем домене и на любом отрезке времени — это глубокий теоретический вызов, над которым его команда долго работала <a class="ts" data-seconds="519" href="#t=519" title="Смотреть с 8:39" aria-label="Смотреть с 8:39"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. В итоге им удалось доказать, что при определенных допущениях регулярности алгоритм способен гарантированно находить квазиоптимальные решения, не нарушая ограничений ни на одном из шагов обучения <a class="ts" data-seconds="584" href="#t=584" title="Смотреть с 9:44" aria-label="Смотреть с 9:44"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
🏎️ От теории к практике: ускорение протонов и настройка роботов 9:44
Разработанные алгоритмы безопасной оптимизации были развернуты непосредственно на швейцарской установке SwissFEL. Аспиранты Йоханнес (Johannes) и Мойнье (Moynier) вместе с коллегой Николь (Nicole) работали в операторской комнате ускорителя, запуская код в реальном времени <a class="ts" data-seconds="597" href="#t=597" title="Смотреть с 9:57" aria-label="Смотреть с 9:57"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
В ходе экспериментов исследователи брали параметры, выставленные экспертами-физиками, намеренно сбивали настройки до ухудшения работы системы, а затем запускали алгоритм для восстановления оптимального режима. Байесовская оптимизация показала значительное превосходство над традиционными методами локального поиска, обеспечив глобальную сходимость при строгом соблюдении рамок безопасности <a class="ts" data-seconds="625" href="#t=625" title="Смотреть с 10:25" aria-label="Смотреть с 10:25"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
После этого успеха методологию Safe BO применили на еще более опасном объекте — высокоинтенсивном протонном ускорителе в том же научном центре <a class="ts" data-seconds="651" href="#t=651" title="Смотреть с 10:51" aria-label="Смотреть с 10:51"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Любая ошибка там чревата мгновенной аварийной остановкой. Алгоритм сумел найти существенно более качественные режимы работы ускорителя, не вызвав ни одного прерывания протонного пучка.
Помимо физических мега-установок, данный метод успешно зарекомендовал себя в робототехнике и промышленности. Его использовали для автоматической настройки параметров усиления высокоточных электродвигателей на производстве, а также для подбора параметров походки четырехногих роботов-квадрупедов <a class="ts" data-seconds="664" href="#t=664" title="Смотреть с 11:04" aria-label="Смотреть с 11:04"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
🧠 Мета-обучение: как извлечь априорные знания из прошлых задач 11:17
Классическая байесовская оптимизация требует от инженера ручного проектирования априорной модели — например, выбора фиксированного ядра гауссовского процесса. Но опыт глубокого обучения и генеративного ИИ доказывает: если данных достаточно, извлечение представлений из самой информации работает лучше, чем ручной дизайн функций <a class="ts" data-seconds="717" href="#t=717" title="Смотреть с 11:57" aria-label="Смотреть с 11:57"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Кроме того, представления, освоенные на одних задачах, можно эффективно адаптировать (дообучать) на новых. Например, модель, обученную на миллионах обычных фотографий, можно быстро и экономно дообучить на распознавание медицинских снимков с использованием малой выборки.
Ученые задались вопросом: можно ли перенести этот принцип на последовательное принятие решений и байесовскую оптимизацию? Ответ лежит в плоскости байесовского мета-обучения (Bayesian meta-learning) <a class="ts" data-seconds="745" href="#t=745" title="Смотреть с 12:25" aria-label="Смотреть с 12:25"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Вместо того чтобы начинать поиск с нуля с абстрактным априорным распределением, алгоритм берет коллекцию схожих задач из смежных областей, выстраивает иерархию и формирует единое мета-априорное знание (hyper-prior) <a class="ts" data-seconds="774" href="#t=774" title="Смотреть с 12:54" aria-label="Смотреть с 12:54"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Накапливая опыт прошлых сессий настройки, система мгновенно адаптируется к новой задаче.
Стандартный подход в индустрии — задавать априорные параметры распределения весов нейросети (например, изотропное гауссовское распределение весов) <a class="ts" data-seconds="826" href="#t=826" title="Смотреть с 13:46" aria-label="Смотреть с 13:46"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. По мнению спикера, у этого метода есть огромный минус: крайне тяжело просчитать, какие именно ограничения и допущения такой шаг накладывает на итоговое пространство функций <a class="ts" data-seconds="839" href="#t=839" title="Смотреть с 13:59" aria-label="Смотреть с 13:59"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. На практике это часто приводит к непредсказуемому поведению ИИ и плохой калибровке.
В качестве альтернативы команда докладчика предложила кодировать априорные допущения напрямую в пространстве функций <a class="ts" data-seconds="852" href="#t=852" title="Смотреть с 14:12" aria-label="Смотреть с 14:12"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Гауссовские процессы удобны тем, что ведут себя понятно: вблизи известных данных они уверены, а по мере удаления от них неопределенность плавно растет. Исследователи решили напрямую обучать модель базового случайного процесса, управляющего распределением наград и ограничений.
Поскольку случайные процессы полностью определяются своими маргинальными распределениями, моделировать их нужно только в тех точках, где они непосредственно вычисляются <a class="ts" data-seconds="909" href="#t=909" title="Смотреть с 15:09" aria-label="Смотреть с 15:09"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Более того, для большинства современных техник приближенного вывода в байесовском глубоком обучении нет необходимости знать само распределение функций — достаточно знать так называемый «скор» (score), то есть градиент логарифма плотности вероятности случайного процесса в исследуемых точках <a class="ts" data-seconds="922" href="#t=922" title="Смотреть с 15:22" aria-label="Смотреть с 15:22"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Для предсказания этого скора ученые задействовали гибкую архитектуру трансформера (transformer-based model) <a class="ts" data-seconds="1000" href="#t=1000" title="Смотреть с 16:40" aria-label="Смотреть с 16:40"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Обучение этой нейросети скорингу осуществляется с помощью метода сопоставления скоров (score matching) — базового математического движка, стоящего за современными диффузионными моделями генерации изображений.
📊 Эксперименты с диффузионным счетом и поиск безопасного баланса 16:54
Разработанную архитектуру на основе диффузионного скора протестировали на широком спектре бенчмарков в условиях жесткого дефицита данных, когда на одну задачу приходится всего несколько примеров. В тестах использовались реальные логи прошлых сессий настройки лазера SwissFEL, а также медицинские базы данных временных рядов пациентов из палат интенсивной терапии (где важно построить общую модель, но кастомизировать ее под конкретного человека) <a class="ts" data-seconds="1054" href="#t=1054" title="Смотреть с 17:34" aria-label="Смотреть с 17:34"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Нейросеть показала высокую точность предсказаний и рекордно низкую ошибку калибровки <a class="ts" data-seconds="1067" href="#t=1067" title="Смотреть с 17:47" aria-label="Смотреть с 17:47"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Теоретические аспекты сходимости этой системы в параметрических режимах исследовала аспирантка команды Парниан (Parnian) <a class="ts" data-seconds="1095" href="#t=1095" title="Смотреть с 18:15" aria-label="Смотреть с 18:15"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Когда речь заходит о безопасности, критически важно гарантировать, что мета-обученная модель выдает консервативные, а не излишне оптимистичные оценки неопределенности. Для этого исследователи ввели управление гиперпараметрами масштаба (дисперсии) и масштаба длины (length scale) <a class="ts" data-seconds="1125" href="#t=1125" title="Смотреть с 18:45" aria-label="Смотреть с 18:45"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Взаимосвязь этих параметров определяет поведение модели:
- Большой length scale: единичные наблюдения вызывают резкое падение неопределенности вокруг точки. Это ускоряет обучение, но может спровоцировать опасное поведение алгоритма, если реальная функция окажется более изменчивой
<a class="ts" data-seconds="1150" href="#t=1150" title="Смотреть с 19:10" aria-label="Смотреть с 19:10"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. - Малый length scale и высокая дисперсия: модель ведет себя максимально консервативно, осторожно продвигаясь по пространству, что гарантирует безопасность, но замедляет поиск.
Чтобы найти идеальный баланс (sweet spot) между скоростью обучения и соблюдением ограничений, ученые предложили алгоритм поиска на Парето-фронте (frontier search) <a class="ts" data-seconds="1258" href="#t=1258" title="Смотреть с 20:58" aria-label="Смотреть с 20:58"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Алгоритм максимизирует информативность модели, опираясь на исторические данные, но жестко следит за тем, чтобы уровень калибровки не падал ниже безопасного лимита. Эксперименты на реальном оборудовании доказали, что использование оптимизированного мета-приора дает колоссальное ускорение сходимости по сравнению с обучением с чистого листа <a class="ts" data-seconds="1298" href="#t=1298" title="Смотреть с 21:38" aria-label="Смотреть с 21:38"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
🎮 Управление на основе моделей: оптимистичное исследование без риска 21:51
Следующим шагом исследователей стала трансляция идей байесовской оптимизации в теорию автоматического управления и в обучение с подкреплением на основе моделей (Model-Based RL). В отличие от оптимизации черного ящика, роботы и динамические системы выдают непрерывный поток наблюдений за своим состоянием. Неизвестная динамика описывается марковским ядром переходов, и байесовская модель призвана оценивать эпистемическую неопределенность относительно того, в каком состоянии окажется робот на шаге $t+1$ при совершении конкретного действия <a class="ts" data-seconds="1378" href="#t=1378" title="Смотреть с 22:58" aria-label="Смотреть с 22:58"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Если запустить робота из начальной точки в целевую, цепочка неопределенности начнет лавинообразно нарастать с каждым шагом вперед. Однако по мере движения и сбора данных доверительные интервалы сужаются. Робот может перепланировать траекторию на лету, становясь менее консервативным <a class="ts" data-seconds="1416" href="#t=1416" title="Смотреть с 23:36" aria-label="Смотреть с 23:36"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
В рамках эпизодического Model-Based RL авторы выстроили следующий цикл: агент совершает раунд в реальном мире, собирает данные, уточняет модель динамики и затем использует накопленную неопределенность для планирования новой стратегии <a class="ts" data-seconds="1500" href="#t=1500" title="Смотреть с 25:00" aria-label="Смотреть с 25:00"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Процесс планирования происходит сугубо виртуально (интроспективно), внутри модели-симулятора. Для этого можно использовать любые мощные алгоритмы безмодельного RL (например, политические градиенты), тратя сколько угодно вычислительных ресурсов процессора перед тем, как совершить физическое действие на реальном роботе <a class="ts" data-seconds="1526" href="#t=1526" title="Смотреть с 25:26" aria-label="Смотреть с 25:26"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Большинство классических алгоритмов (таких как PILCO или PETS) при планировании просто усредняют траектории по ансамблю моделей динамики, что эквивалентно тривиальному адаптивному управлению <a class="ts" data-seconds="1613" href="#t=1613" title="Смотреть с 26:53" aria-label="Смотреть с 26:53"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Команда спикера разработала метод оптимистичного исследования среды, преодолевающий этот недостаток <a class="ts" data-seconds="1568" href="#t=1568" title="Смотреть с 26:08" aria-label="Смотреть с 26:08"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Идея графически иллюстрируется одномерной схемой: агенту в виртуальном симуляторе позволяют буквально «контролировать свое везение» <a class="ts" data-seconds="1726" href="#t=1726" title="Смотреть с 28:46" aria-label="Смотреть с 28:46"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. В пределах одношагового доверительного интервала неопределенности динамики агент сам выбирает ту точку следующего состояния, которая ему наиболее выгодна. Эта процедура математически перепараметризует неопределенность в управляемый параметр новой модифицированной функции динамики $\tilde{f}$ <a class="ts" data-seconds="1740" href="#t=1740" title="Смотреть с 29:00" aria-label="Смотреть с 29:00"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Задача оптимистичного поиска сводится к стандартному динамическому программированию, где можно эффективно применять метод политического градиента.
На классической задаче раскачивания перевернутого маятника (inverted pendulum) алгоритм продемонстрировал молниеносную скорость обучения с нуля <a class="ts" data-seconds="1782" href="#t=1782" title="Смотреть с 29:42" aria-label="Смотреть с 29:42"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Не зная законов физики, робот в первых раундах падал, но быстро собирал данные по пространству состояний и находил идеальную траекторию подъема <a class="ts" data-seconds="1809" href="#t=1809" title="Смотреть с 30:09" aria-label="Смотреть с 30:09"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Метод значительно превзошел по эффективности стратегии на основе сэмплирования Томсона и жадные подходы <a class="ts" data-seconds="1865" href="#t=1865" title="Смотреть с 31:05" aria-label="Смотреть с 31:05"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Оптимистичный поиск критически необходим в жестких условиях, когда задействованы штрафы за чрезмерные усилия актуаторов — в таких сценариях стандартные алгоритмы RL пугаются штрафов и просто застывают на месте, тогда как перепараметризованный алгоритм продолжает находить эффективные лазейки для достижения цели <a class="ts" data-seconds="1893" href="#t=1893" title="Смотреть с 31:33" aria-label="Смотреть с 31:33"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
🛡️ Безопасность на основе пикселей и преодоление разрыва между симуляцией и реальностью 32:25
Аналогичный подход с перепараметризацией неопределенности исследователи адаптировали для марковских процессов принятия решений с ограничениями (Constraint MDPs). В этой схеме агент при поиске стратегии внутри симулятора обязан быть оптимистичным в отношении исследования наград, но предельно пессимистичным в отношении нарушения безопасности <a class="ts" data-seconds="1988" href="#t=1988" title="Смотреть с 33:08" aria-label="Смотреть с 33:08"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Эффективность подхода была доказана на сложном робототехническом бенчмарке Safety-Gym, где виртуальные объекты (точка, тележка, квадрупед) должны ориентироваться в пространстве, нажимать кнопки и перемещать коробки, ориентируясь исключительно на изображение с фронтальной камеры (обучение напрямую из пикселей) <a class="ts" data-seconds="2031" href="#t=2031" title="Смотреть с 33:51" aria-label="Смотреть с 33:51"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Модель успешно справилась с частичной наблюдаемостью среды, показав высокую скорость обучения и гарантируя безопасное поведение в процессе тренировки, тогда как безмодельные алгоритмы требовали на несколько порядков больше итераций и постоянно нарушали ограничения <a class="ts" data-seconds="2102" href="#t=2102" title="Смотреть с 35:02" aria-label="Смотреть с 35:02"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Финальным аккордом презентации стал эксперимент с парковкой задним ходом миниатюрного гоночного автомобиля <a class="ts" data-seconds="2157" href="#t=2157" title="Смотреть с 35:57" aria-label="Смотреть с 35:57"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Задача осложнена нелинейным трением, проскальзыванием шин и сложной динамикой колес. Базовый алгоритм Model-Based RL обучается этой задаче с нуля примерно за 20 эпизодов <a class="ts" data-seconds="2187" href="#t=2187" title="Смотреть с 36:27" aria-label="Смотреть с 36:27"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Если применить классический подход из теории управления — взять простую физическую модель велосипеда (bicycle model) и откалибровать ее параметры через идентификацию систем (sys id), — возникнет неизбежный разрыв между симуляцией и реальностью (sim-to-real gap) <a class="ts" data-seconds="2239" href="#t=2239" title="Смотреть с 37:19" aria-label="Смотреть с 37:19"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Машинка будет парковаться близко к цели, но не идеально, поскольку простая физика не учитывает микроэффекты скольжения шин.
Чтобы убрать этот разрыв, ученые задействовали байесовское мета-обучение. Они взяли несовершенный симулятор велосипеда и превратили его в нейросетевой априорный фильтр <a class="ts" data-seconds="2323" href="#t=2323" title="Смотреть с 38:43" aria-label="Смотреть с 38:43"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Нейросеть обучалась на скорах симулятора, вбирая в себя базовые законы физики.
В результате реальный робот уже в самом первом заезде парковался в правильном направлении, а для полной идеальной адаптации к трению и скольжению на реальном треке ему потребовалось всего 10 эпизодов <a class="ts" data-seconds="2348" href="#t=2348" title="Смотреть с 39:08" aria-label="Смотреть с 39:08"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Данный гибридный метод показал лучшую точность предсказания состояний и превзошел как чистые нейросети, так и классические сероящичные (gray-box) модели динамики <a class="ts" data-seconds="2424" href="#t=2424" title="Смотреть с 40:24" aria-label="Смотреть с 40:24"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Подводя итог, спикер подчеркнул, что ключевым фронтиром в создании безопасного ИИ является способность алгоритмов четко осознавать границы собственного незнания <a class="ts" data-seconds="2501" href="#t=2501" title="Смотреть с 41:41" aria-label="Смотреть с 41:41"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Это требование актуально как для робототехники, так и для современных больших фундаментальных моделей. Чтобы продолжить масштабирование этих концепций, команда планирует задействовать мощности суперкомпьютера следующего поколения в Лугано (Швейцария), оснащенного передовыми графическими процессорами <a class="ts" data-seconds="2527" href="#t=2527" title="Смотреть с 42:07" aria-label="Смотреть с 42:07"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
❓ Вопросы и ответы: имитационное обучение и каузальный анализ 42:34
После завершения доклада слушатели задали автору несколько уточняющих вопросов.
Вопрос об имитационном обучении (Imitation Learning): Один из участников поинтересовался, не теряются ли строгие гарантии безопасности, если вместо интерактивного RL использовать обучение по демонстрациям эксперта <a class="ts" data-seconds="2567" href="#t=2567" title="Смотреть с 42:47" aria-label="Смотреть с 42:47"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Спикер согласился, что фундаментальное ограничение имитационного обучения заключается в том, что агент принципиально не может стать лучше, чем увиденные им демонстрации <a class="ts" data-seconds="2587" href="#t=2587" title="Смотреть с 43:07" aria-label="Смотреть с 43:07"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Тем не менее эти подходы можно эффективно комбинировать: например, использовать имитационное обучение для построения грамотного скрытого пространства признаков (latent space), а затем запускать на его основе алгоритмы безопасной байесовской оптимизации.
Вопрос о гранулярности действий: Слушатель спросил, можно ли оценивать неопределенность не для симулятора целиком, а на более детальном уровне — например, раздельно для каждого мотора многоколесного робота <a class="ts" data-seconds="2639" href="#t=2639" title="Смотреть с 43:59" aria-label="Смотреть с 43:59"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.
Докладчик назвал эту идею отличным вектором развития, отметив, что такое разделение ведет к области причинно-следственного анализа (causal discovery) <a class="ts" data-seconds="2691" href="#t=2691" title="Смотреть с 44:51" aria-label="Смотреть с 44:51"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>. Его команда уже ведет исследования в сфере причинно-следственной байесовской оптимизации на основе моделей (Model-Based Causal BO), которая изучает локальные эффекты конкретных узлов системы <a class="ts" data-seconds="2704" href="#t=2704" title="Смотреть с 45:04" aria-label="Смотреть с 45:04"><svg viewBox="0 0 24 24" width="14" height="14" fill="currentColor" aria-hidden="true"><path d="M8 5v14l11-7z"/></svg></a>.