В своем видеообзоре популярный IT-блогер Янник Килчер (Yannic Kilcher) подробно разбирает научную статью исследовательской лаборатории DeepMind, посвященную созданию агентов с дополненным воображением (Imagination-Augmented Agents, I2A) для глубокого обучения с подкреплением. Разработчики предложили гибридный подход, который позволяет искусственному интеллекту самостоятельно моделировать окружающий мир и планировать свои действия в будущем. Ключевая ценность технологии заключается в способности агента эффективно принимать решения даже в тех случаях, когда его внутреннее представление о мире содержит серьезные ошибки и неточности.
🤖 Два подхода к обучению с подкреплением: Model-Based и Model-Free 0:57
Чтобы объяснить суть новой архитектуры, Янник Килчер сопоставляет два классических метода в обучении с подкреплением (Reinforcement Learning).
Первый метод — это подход на основе модели (Model-Based). В данном сценарии у агента есть точное математическое или алгоритмическая описание среды, напоминающее «черный ящик». Работает это следующим образом:
- На вход системе подается текущее состояние среды $s$ и предполагаемое действие $a$.
- Модель среды точно просчитывает и выдает следующее состояние $s'$.
- Агент может заранее перебрать различные варианты действий в симуляции, чтобы определить, какая траектория приведет его к желаемому финальному результату.
Второй метод — это свободный от модели подход (Model-Free). Здесь агент лишен предварительных знаний об устройстве мира. Вместо этого он использует глубокую нейросеть, которая принимает текущее состояние и сразу выдает рекомендацию по действию, основываясь исключительно на накопленном опыте и полученных ранее наградах. По словам ведущего, статья DeepMind предлагает инновационную комбинацию обоих подходов, объединяя их сильные стороны в рамках одной нейросетевой архитектуры.
🧠 Архитектура агентов с дополненным воображением (I2A) 2:26
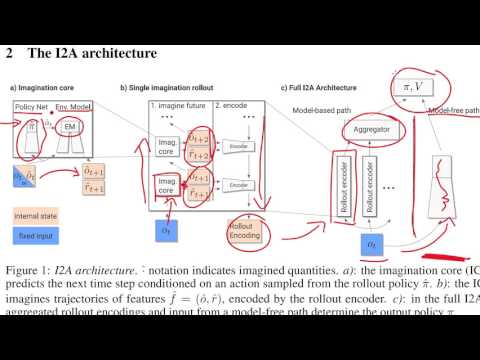
Архитектура I2A разделяет процесс принятия решений на два параллельных потока, которые впоследствии объединяются финальной стратегией.
С правой стороны схемы находится классический Model-Free путь. Текущее состояние среды напрямую пропускается через нейросеть, которая генерирует базовое действие на основе мгновенной оценки ситуации. Левая же часть схемы представляет собой принципиально новый «путь воображения» (imagination path), состоящий из кодировщиков траекторий (rollout encoders).
Внутри этого блока агент буквально симулирует возможные варианты будущего. Ядром этой системы является так называемое ядро воображения (Imagination Core), которое состоит из следующих элементов:
- Внутренняя модель среды (environment model), которую агент самостоятельно обучает на основе ранее увиденного опыта.
- Локальная нейросеть стратегии (policy network), выбирающая воображаемые действия.
Модель среды непрерывно обучается предсказывать следующее состояние и следующую награду на основе совершаемых шагов.
🔄 Преодоление бесконечной рекурсии и сборка «воображаемых» данных 4:20
В процессе симуляции будущего возникает серьезная техническая проблема: если для выбора действий внутри воображения использовать основную сложную нейросеть, система уйдет в бесконечную рекурсию. Для решения этой проблемы инженеры DeepMind применили изящный трюк.
Внутри ядра воображения используется уменьшенная, чисто Model-Free копия основной сети. Янник Килчер поясняет механизм ее обучения: эта маленькая сеть просто учится копировать поведение и ответы большой финальной сети, беря те же входные данные. Это позволяет агенту быстро симулировать цепочки шагов в уме, не перегружая вычисления.
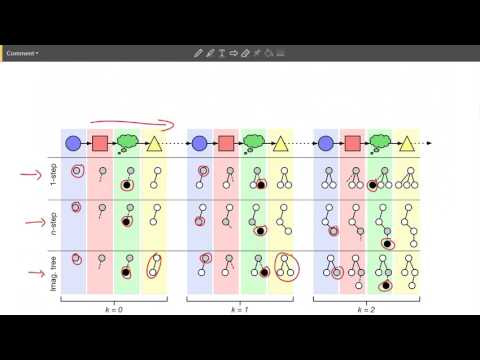
Процесс формирования «воображаемой» траектории выглядит следующим образом:
- Агент берет текущее реальное состояние, передает его в модель среды и с помощью маленькой сети выбирает воображаемое действие.
- Модель выдает симулированное новое состояние и награду.
- Этот шаг повторяется последовательно несколько раз, формируя цепочку — так называемый rollout.
- Вся последовательность состояний и наград кодируется с помощью LSTM-нейросети в единый векторный эмбеддинг.
По задумке авторов, этот итоговый вектор успешно инкапсулирует в себе информацию о том, насколько успешным и перспективным окажется данный вариант будущего. Если агент просчитывает несколько альтернативных вариантов будущего, все полученные эмбеддинги агрегируются (в данном случае просто конкатенируются) и передаются в главный сумматор. Главный агрегатор сопоставляет сигналы от Model-Free ветки и результаты воображения. Если воображение кажется ему неточным, система может полностью довериться классическому Model-Free пути, а если симуляция выглядит надежной — скорректировать действия на основе планов. Вся система обучается сквозным образом (end-to-end).
📦 Эксперименты на Sokoban: планирование на уровне пикселей 8:42
Для демонстрации возможностей алгоритма исследователи выбрали классическую головоломку «Сокобан» (Sokoban). В этой игре управляемый нейросетью зеленый аватар должен расставить коричневые ящики на красные квадраты.
Эта игра представляет огромную сложность для стандартного ИИ по следующим причинам:
- Процедурная генерация: каждый уровень создается случайно, поэтому агент не может просто зазубрить последовательность шагов.
- Необратимость ошибок: если игрок случайно затолкает ящик в угол, его будет невозможно вытащить обратно. Игра будет безнадежно испорчена, что требует обязательного предварительного планирования.
Особо важной деталью, по мнению Янника Килчера, является то, что разработчики сознательно не закладывали в модель правила игры. Нейросеть не знает математических законов «Сокобана» — она получает на вход исключительно «сырые» пиксели изображения. Симулируя будущее, архитектура I2A вынуждена генерировать воображаемую картинку также на уровне пикселей, пытаясь предугадать, как изменится изображение после хода. С технической точки зрения метод остается свободным от модели (model-free), так как жестко закодированных правил мира в нем нет.
📊 Критика бенчмарков и глубина планирования 10:37
Анализируя графики эффективности, Янник Килчер отмечает любопытную закономерность: точность и результативность агента выходят на плато уже после 5 шагов воображения вглубь. При этом стандартная игровая сессия в «Сокобан» длится около 50 шагов. Таким образом, планирование всего на 5 ходов вперед уже дает колоссальное преимущество для успешного прохождения.
Тем не менее, ведущий высказывает критику в адрес методологии сравнения моделей, представленной в статье DeepMind. Авторы сравнивали I2A с так называемой «Copy Model» (моделью копирования), чтобы уравнять количество параметров в сетях. В этой базовой модели блок симуляции среды просто выдает на выходе ровно то же самое состояние, что получил на входе, утверждая, что мир никак не изменился после действия.
Янник Килчер оценивает такое сравнение скептически: по его мнению, в Copy Model вся ветка воображения фактически становится бесполезной, и хотя формально количество параметров совпадает, реальной пользы они не приносят. Соответственно, превосходство I2A над таким соперником закономерно, но не совсем честно отражает эффективность архитектуры. Также блогер обратил внимание на то, что модель среды обучалась предварительно (pre-training) с помощью уже готового Model-Free агента, а не с нуля в сквозном режиме. Ведущий предполагает, что разработчики наверняка пробовали обучить все сразу, но столкнулись с неуверенной сходимостью алгоритма, из-за чего и прибегли к предобучению.
📉 Стойкость к визуальным галлюцинациям и перенос знаний 13:24
Одним из главных триумфов архитектуры I2A стала ее устойчивость к ошибкам симуляции. Когда авторы намеренно недообучили модель среды, она начала выдавать искаженную пиксельную графику: на кадрах «воображения» дублировались объекты, персонажи застревали внутри стен, а ящики размножались.
Эксперимент показал радикальное различие между I2A и классическими методами планирования:
- Традиционный планировщик на основе выборки Монте-Карло (Monte Carlo sampler planner), столкнувшись с плохой моделью среды, полностью теряет эффективность, а его показатели катастрофически падают.
- Агент I2A практически не пострадал от «галлюцинаций» модели среды. Единственным минусом стало то, что ему потребовалось чуть больше времени, чтобы выйти на пиковые показатели точности.
Это доказывает, что верхний агрегатор успешно отсеивает бред сломанного воображения. Дополнительные тесты в играх стиля Pacman подтвердили, что обученную модель воображения можно эффективно переносить на другие конфигурации задач в рамках того же игрового мира (transfer learning). Кроме того, архитектура продемонстрировала выдающиеся результаты в условиях редких, разреженных наград (sparse rewards). Способность заглядывать в будущее позволяет агенту находить цели там, где обычные алгоритмы бесцельно блуждают в неведении. В заключение Янник Килчер подчеркивает, что считает метод крайне удачным и элегантным, поскольку он изящно комбинирует разрозненные концепции современного машинного обучения.